Matt Hink nailed it with this tweet:
I’ve said it before, I’ll say it again: Being A Programmer basically requires you to deal with extended periods of feeling like a moron punctuated by brief periods of feeling like a goddamn genius.
— Matt Hink (@mhink1103) May 5, 2018
Working with code can be a frustrating experience: one minute you’re power-drunk, amazed by your own cleverness; the next you’re desperately searching Stackoverflow for an answer to some obscure issue that has completely derailed your project.
While we’d all prefer to work in a frictionless, flowing state of mind where projects progress smoothly, this is not the world we live in. We all get stuck from time to time - in fact, it probably happens to many of us a lot more than we’d care to admit.
To a certain extent coding and being stuck are two sides of the same coin. This post explores an idea of how to get the most out of the Being Stuck Experience™ by (you guessed it) writing blog posts!
Re-framing
One strategy that seems to help is to re-frame roadblocks as opportunities to share new knowledge with others. The popularity of blogging and tweeting about R is a testament to the benefits of this approach: you struggle, you overcome, you share, and you build recognition by helping others. Shifting the focus from overcoming the immediate problem to expanding your understanding makes it easier to be patient with yourself. And as an added bonus, the process of writing up your solution helps reinforce the lesson in your own mind and creates an easily accessible resource to return to when you inevitably forget how you solved the problem.
Example
Here is a recent example of this situation from my work at Futurewise.
I needed a list of the names of each government agency in King County, Washington. Luckily, someone had created this exact list and posted it as a dataset on King County’s public data portal:
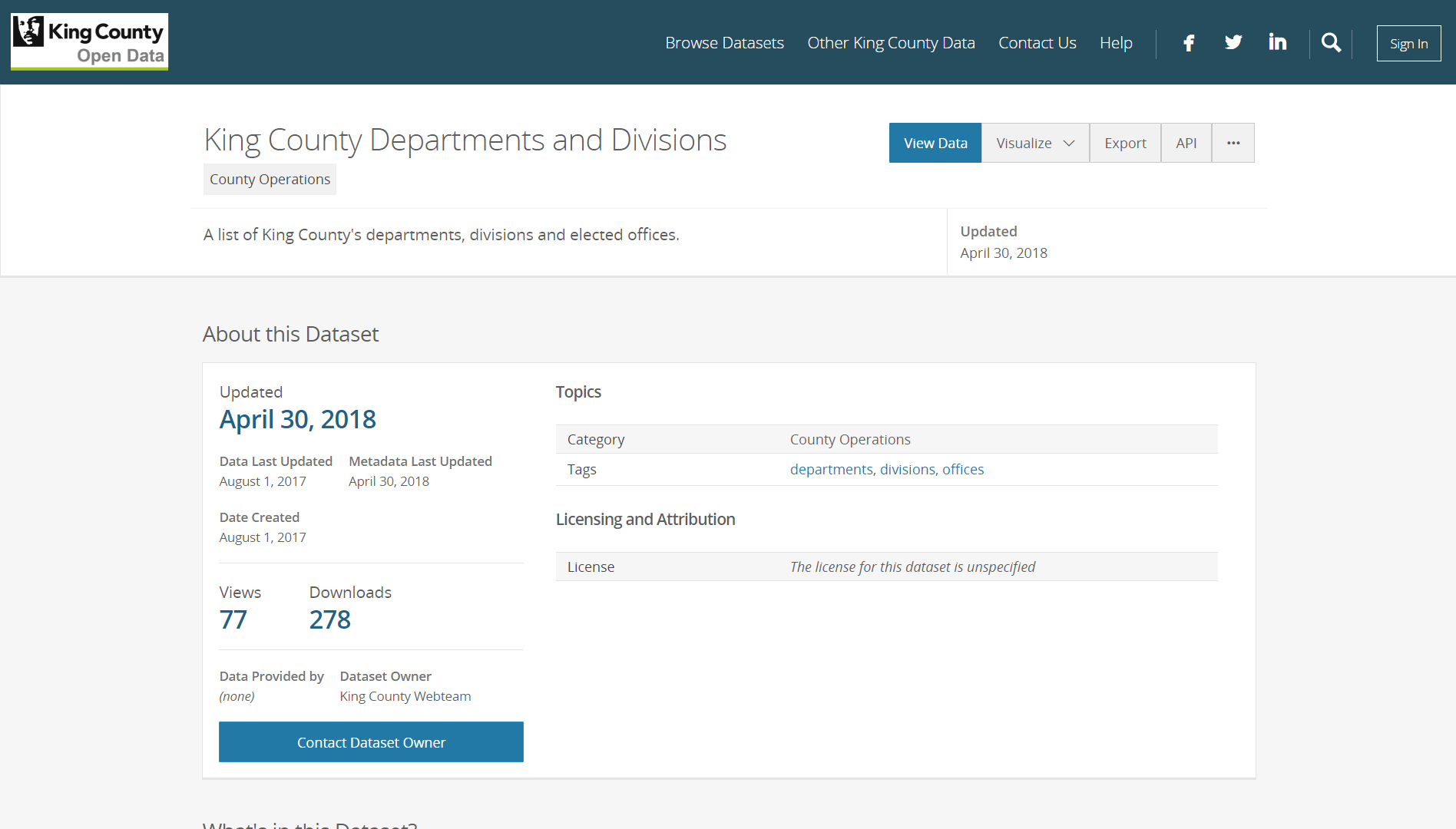
Socrata, the open data platform where this information is hosted, made it easy to access the dataset:
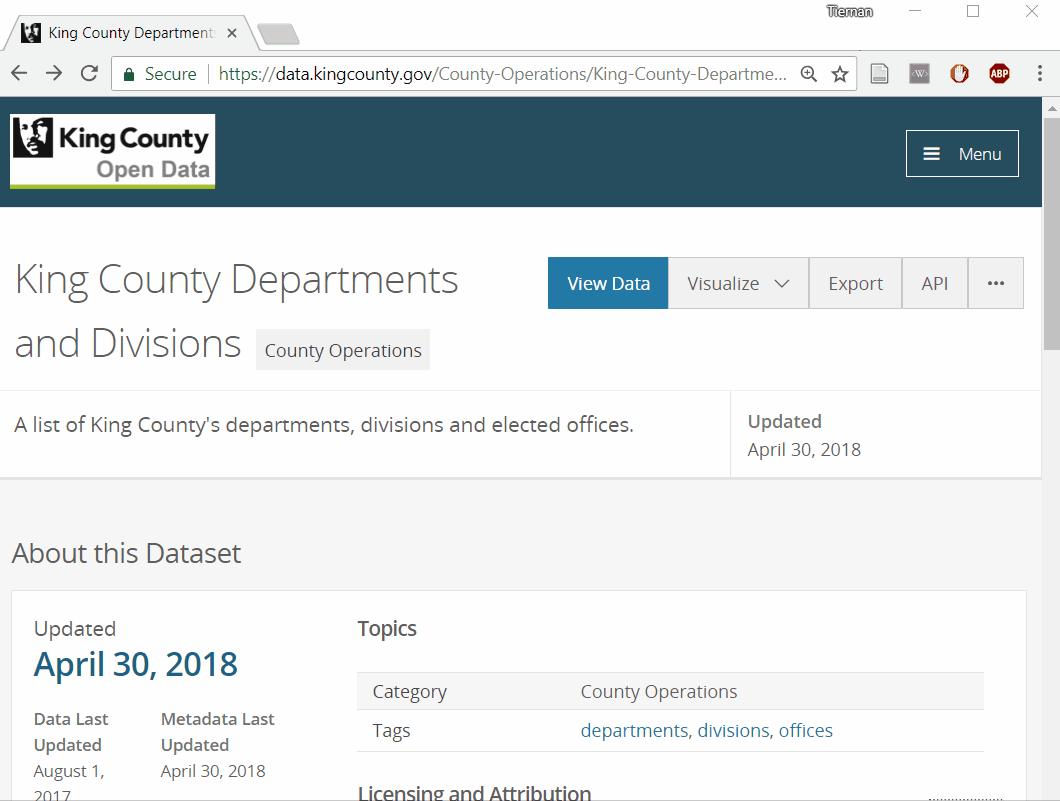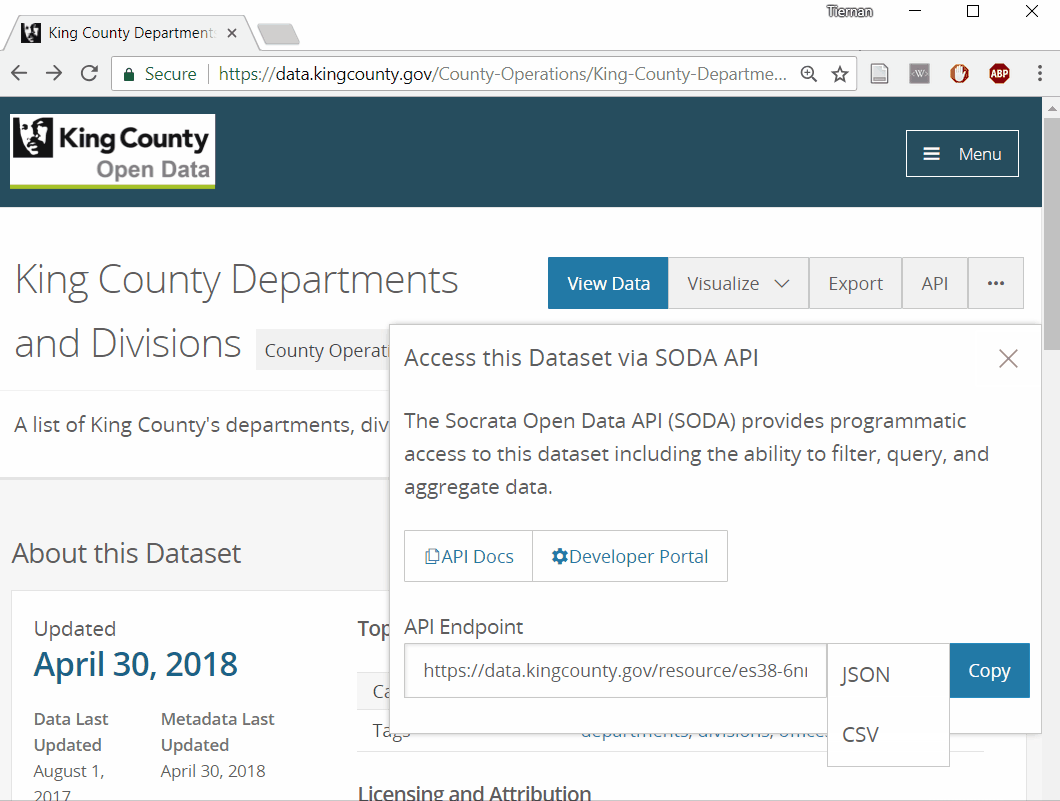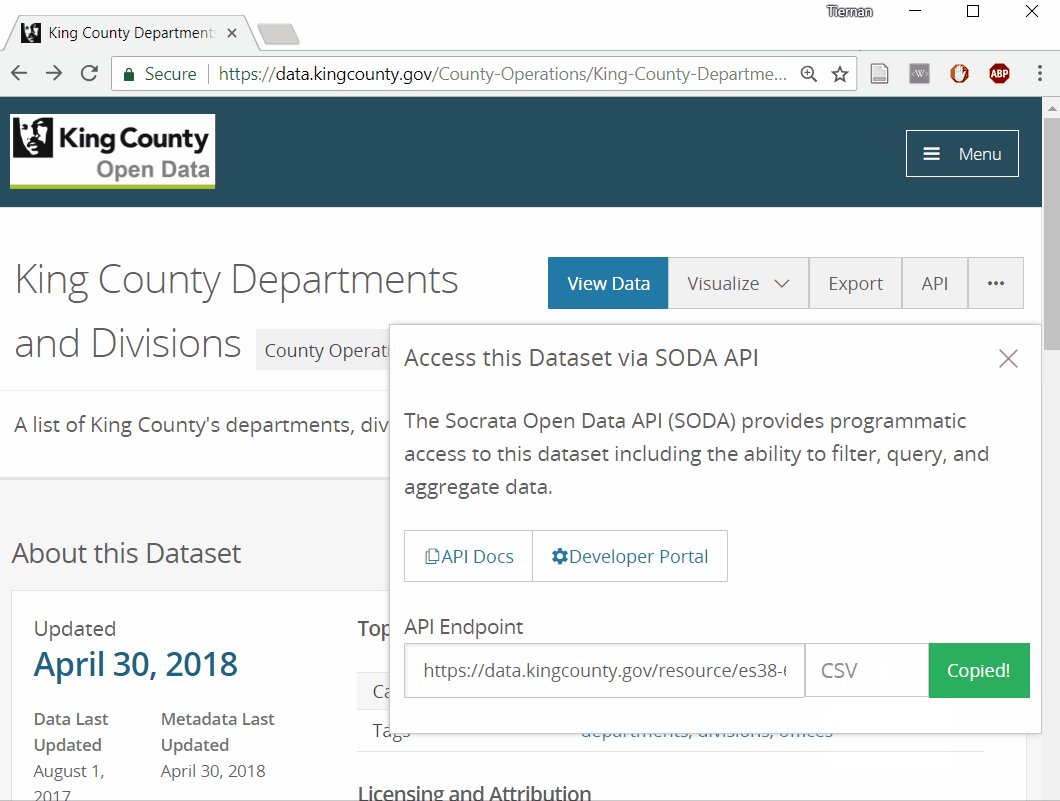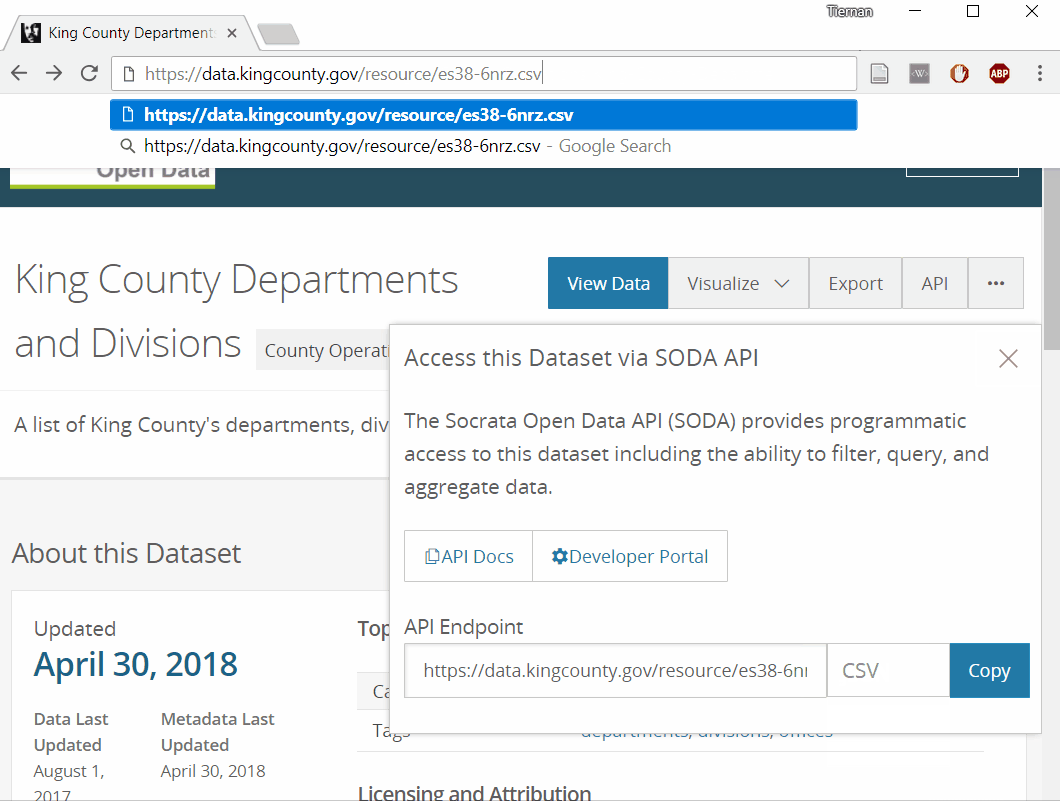
But once the data was loaded into R a problem emerged: unexpected unicode characters (e.g., <U+200B>).
library(tidyverse)
csv_url <- "https://data.kingcounty.gov/resource/es38-6nrz.csv"
agencies <- read_csv(csv_url)
print(as.data.frame(agencies[1:5,]))
## department
## 1 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 2 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 3 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 4 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 5 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## division
## 1 <NA>
## 2 Office of the Executive
## 3 Office of Performance, Strategy and Budget
## 4 Office of Labor Relations<U+200B>
## 5 Office of Economic and Financial AnalysisThese happened to be “invisible” zero-width space characters which are used in computerized typesetting to control word spacing and line-breaks 1. I wasn’t working on a tight deadline with this particular project, so I decided to spend a little time cleaning up the data. But that proved harder than expected.
R’s package ecosystem provides tools for working with text2 as well as unicode3. My first approach was to try to trim the pesky invisible spaces using the stringr package. That didn’t work:
zwsp_pattern <- "<U+200B>"
agencies %>%
mutate_all(funs(str_replace_all(.,zwsp_pattern,""))) %>%
slice(1:5) %>%
as.data.frame()
## department
## 1 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 2 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 3 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 4 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## 5 <U+200B><U+200B>King County Executive<U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B><U+200B>
## division
## 1 <NA>
## 2 Office of the Executive
## 3 Office of Performance, Strategy and Budget
## 4 Office of Labor Relations<U+200B>
## 5 Office of Economic and Financial AnalysisFrustrated, I turned to Google:
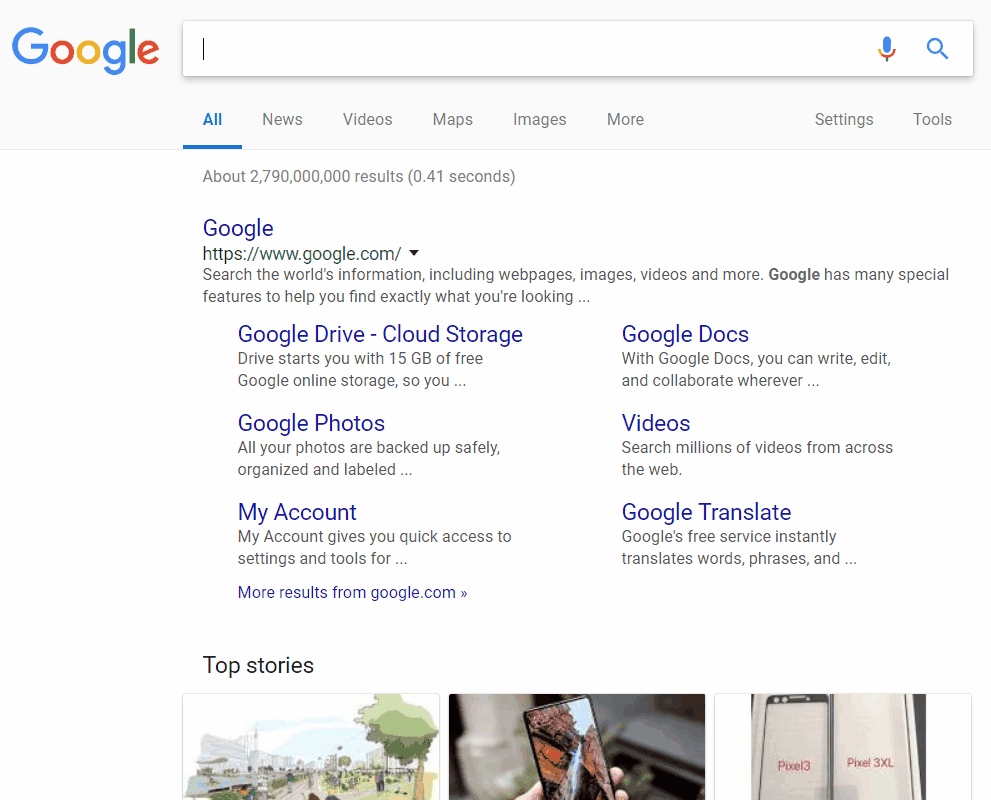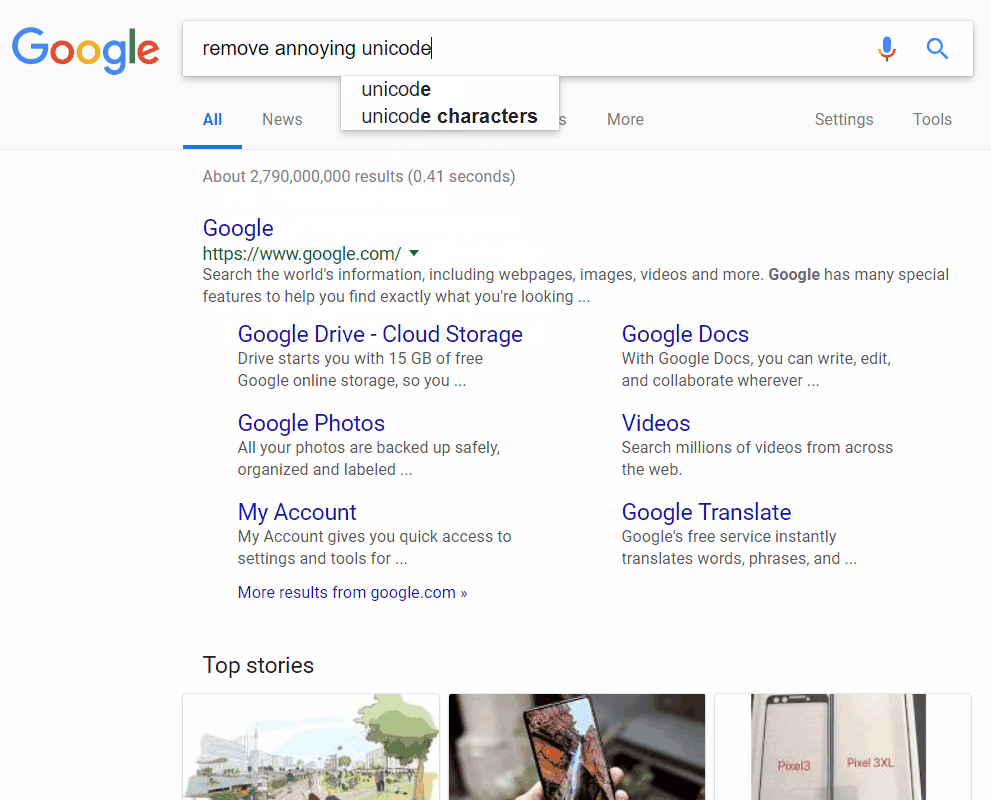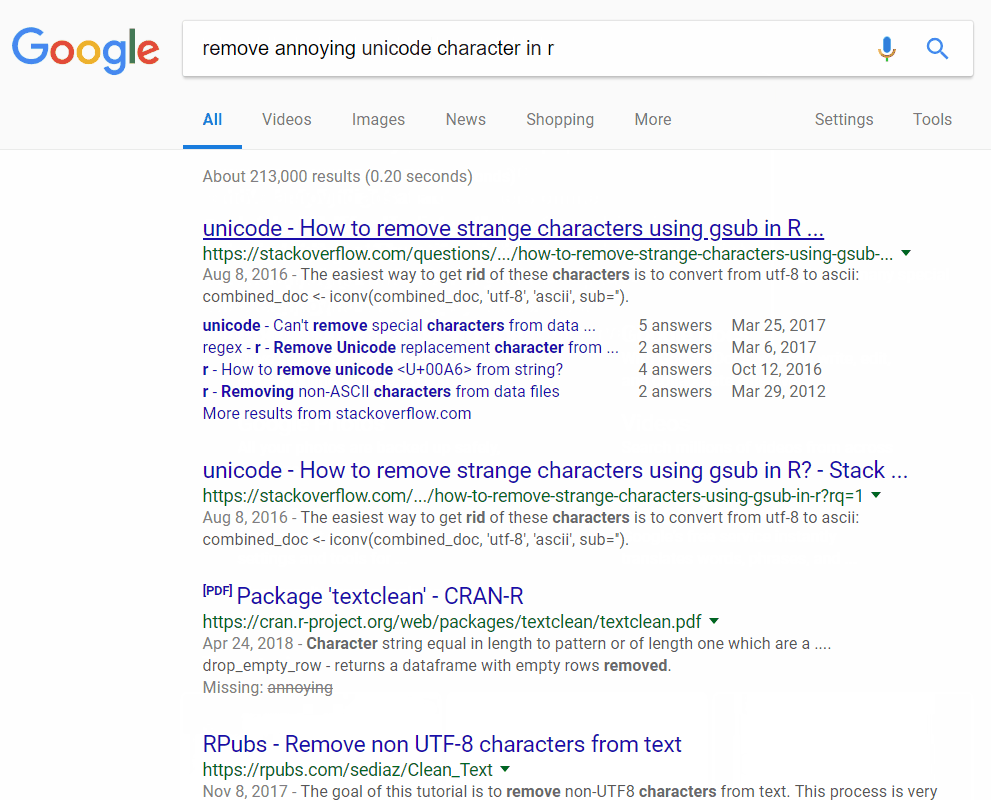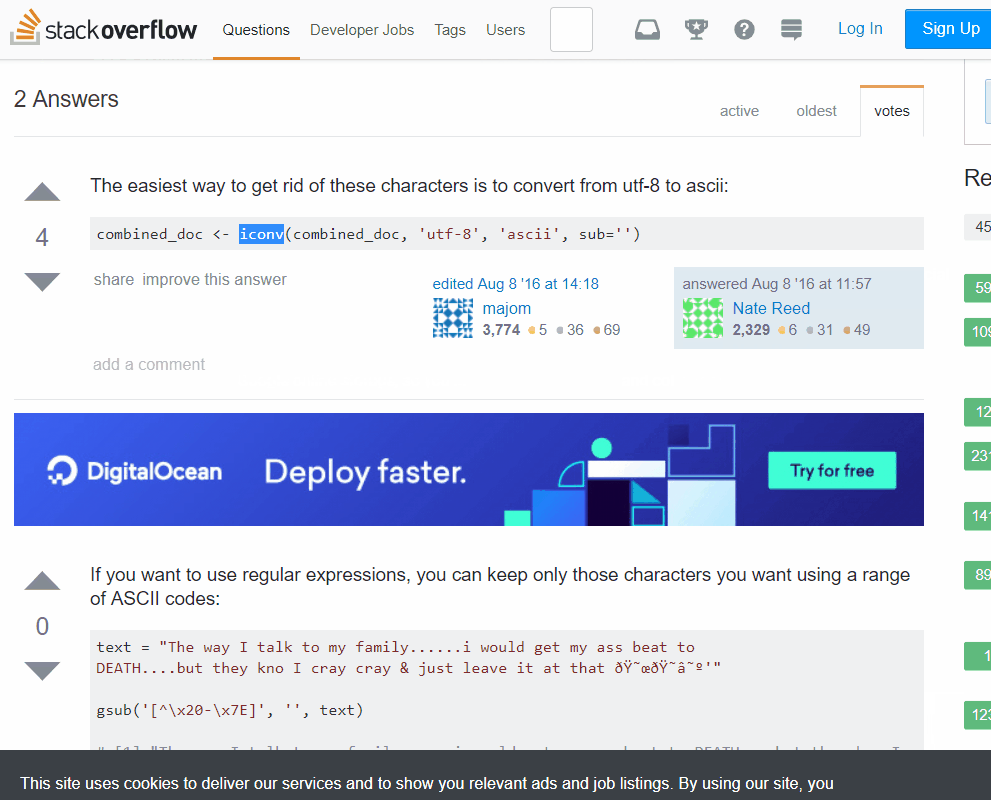
The first suggested link was a similar question on Stackoverflow. I gave the top-voted solution a try and was pleased with the result:
agencies %>%
mutate_all(funs(iconv(.,'utf-8', 'ascii', sub=''))) %>%
slice(1:5) %>%
as.data.frame()
## department division
## 1 King County Executive <NA>
## 2 King County Executive Office of the Executive
## 3 King County Executive Office of Performance, Strategy and Budget
## 4 King County Executive Office of Labor Relations
## 5 King County Executive Office of Economic and Financial AnalysisAt this point I had resolved the immediate problem and could move on but a question was bugging me: why was my first approach unsuccessful? Converting all of the UTF-8 characters to ASCII worked for this use case but it is pretty heavy-handed - what if I only wanted to remove the zero-width escapes?
With these questions in mind, I decided to dig into the problem a little further. My first step was to consult the Regular Expressions cheatsheet from RStudio’s Cheatsheet collection:

Oddly, there was no mention of how to target unicode characters. Googling “r regex unicode” led me to the stringr vignette which contained the answer:
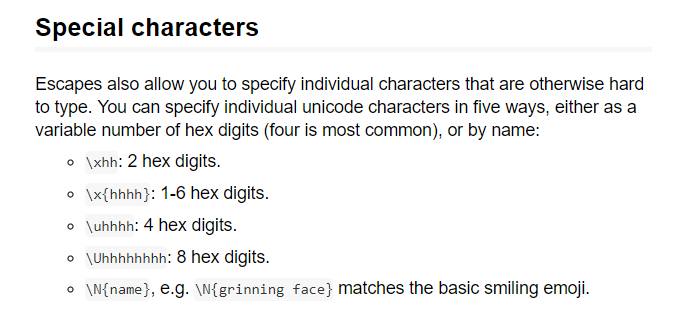
Unicode characters can be specified in the five ways shown above. In order to target this pattern in a regular expression, the leading front-slash needs to be “escaped” with another front-slash like so: \\uhhhh.
With the correct regular expression my original approach successfully removed the zero-width spaces:
zwsp_pattern <- "\\u200b"
agencies %>%
mutate_all(funs(str_replace_all(.,zwsp_pattern,""))) %>%
slice(1:5) %>%
as.data.frame()
## department division
## 1 King County Executive <NA>
## 2 King County Executive Office of the Executive
## 3 King County Executive Office of Performance, Strategy and Budget
## 4 King County Executive Office of Labor Relations
## 5 King County Executive Office of Economic and Financial AnalysisSo it turned out that this unicode problem was a fairly minor roadblock in the end. If you work with code regularly you no doubt encounter and overcome this type of obstacle on a daily basis. I took the new knowledge gained while troubleshooting this issue and consolidated it into a short note in the Notepad section of this site: “Removing Pesky Unicode Zero-Width Spaces”
And then I moved on with my project, confident that I could tackle any further unicode issues that might arise and that the extra time taken to dive into the problem was well-spent. Not only had I solved the immediate problem and improved my understanding of the tools needed to solve it, but I also captured this new understanding in a way that could potentially benefit others - including myself when I inevitably forget this lesson and need to re-learn it!
Conclusion
Re-framing roadblocks as shareable learning opportunities is a powerful idea: it provides an incentive for gaining a richer understanding of programming fundamentals and/or specific tools while mitigating the impact of the uncomfortable (yet all-too-common) feeling of being stuck on a project.
It is important, however, to point out the risk of this approach: the endless pursuit of an elusive solution down one rabbit hole after another can turn into another form of procrastination. It takes a certain amount of self-restraint to avoid this trap, but in my experience this gets easier over time and you can increase your willpower by exercising it like a muscle.
The product of these self-guided explorations can take many forms:
- a gist or short note to youself
- a post on Stackoverflow or the RStudio Community Forum
- a tweet or blog post
- a Youtube screencast4
I recently started tracking my own lessons-learned in the Notepad section of this blog. It’s currently pretty sparse but I plan to add to it over time - there’s certainly no shortage of new roadblocks to overcome.
DIY & Feedback
If you’d like to reproduce this example on your own computer please download the gist.
Questions, feedback, and suggested improvements are always welcome!
Resources
stringrvignette- Stackoverflow question about removing unicode characters: How to remove strange characters using gsub in R?
- FileFormate.Info: A to Z Index of Unicode Characters: starting with ‘A’
Wikipedia: “Zero-width space”“↩
Encoding functions/packages:
base::iconv();Unicode;utf8↩Youtube channels to follow: Hadley Wickham; Roger Peng↩