
Creating engaging data graphics takes a ton of work!
Case in point: the image above took me half a day of data wrangling, documentation skimming, and parameter tweaking before I got it right - and that’s just one plot!
Most of my data visualization work serves a single purpose: to help me better understand the structure and content of the data. In the early stages of an analysis I produce many quick’n’dirty plots and try to avoid getting attached to any single idea. But eventually I pick one or two to be refined into polished graphics and that work requires a different set of tools and priorities.
This post demonstrates a few of the techniques I use when I’m preparing a plot for an external audience (as opposed to one that is just meant for me). Below, I follow the path of the North Carolina Counties plot (see above) from rough sketch to final draft, highlighting some handy functions, packages, and code patterns along the way. With any luck, this may be of some use to others and at the very least it will help me remember some of these obscure ggplot2 tricks.
Enough introduction - let’s begin.
The Example Dataset: The Counties of North Carolina
When I sat down to write this post I considered several different datasets before eventually deciding to use the North Carolina Sudden Infant Death Syndrome (SIDS) dataset (nc). I’ll admit that may seem like an odd choice for an example, as the data are related neither to the focus of my career (urban planning) nor to the place I live (Seattle, Washington). I basically have no connection to these data, so why use them in a post about creating graphics?
I want to introduce nc for three reasons:
- Easy Access: It’s easy to access because it comes bundled in the simple features (
sf) package.1 - Relatable Geometries: The county boundaries are polygon geometry objects, which are one of the more common types of spatial objects and are easy for viewers to understand.
- Reprex-ible: The dataset is small and simple enough to be used in a reprex2, which means that it can be easily adapted to illustrate a problem and used get help from others.
But given my lack of public health expertise I doubt I’ll be able to produce an informative graphic with the SIDS data contained in the dataset.3 Instead, I’ll search for more accessible data (which can be joined to nc’s spatial geometries) in my go-to open data portal:
Prompted by the Wikipedia search bar autocomplete, I find that the “List of counties in North Carolina” page contains a table with several columns that might be interesting to visualize in a plot:
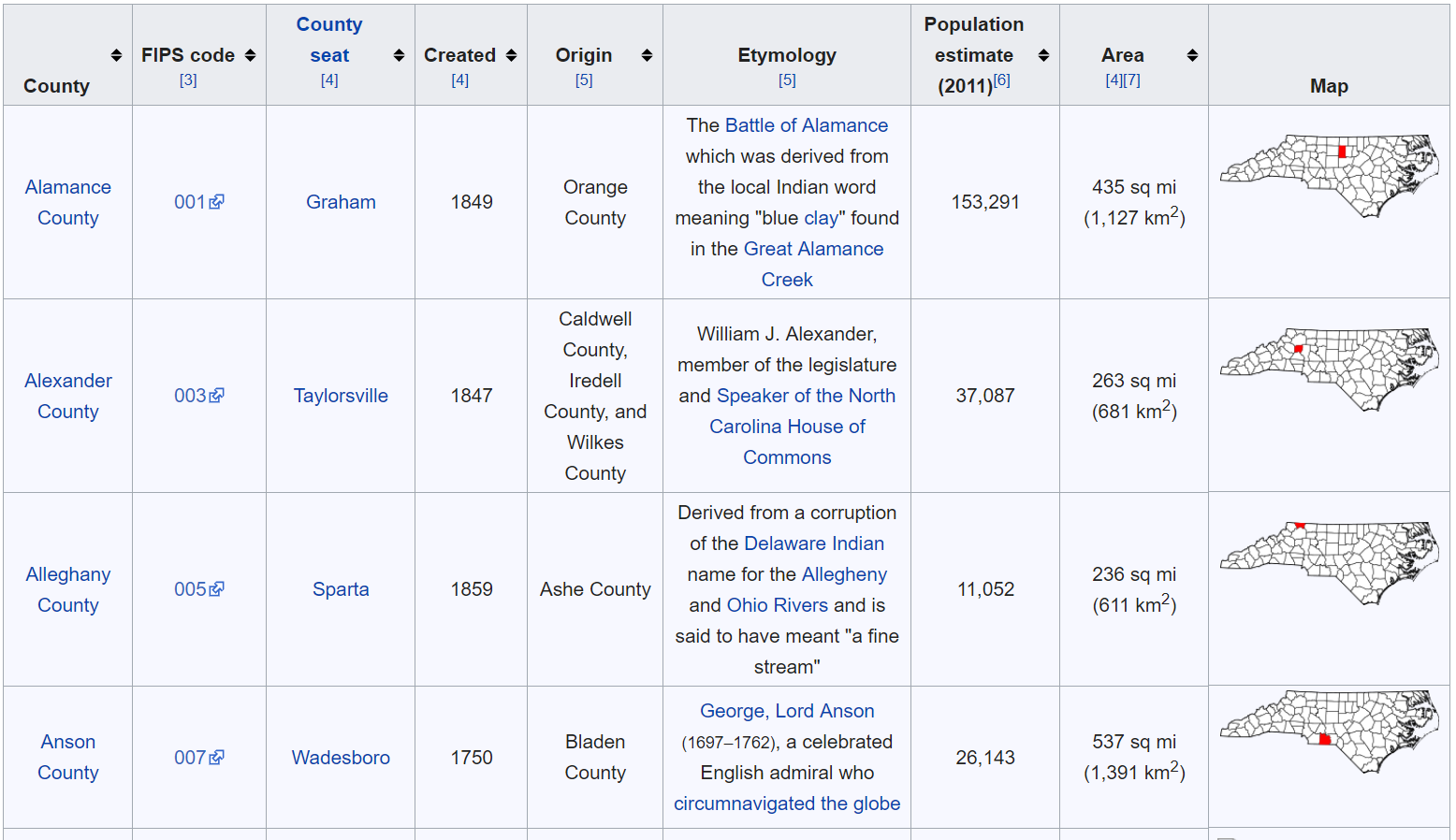
With the spatial data from nc and the descriptive data from the Wikipedia table, I’m ready to begin the process of creating a data visualization graphic.
Loading the data
We’ll use functions from several packages during this post, so the first step is to load the packages:
library(ggrepel)
library(patchwork)
library(rvest)
library(janitor)
library(sf)
library(tidyverse) As I said before, the nc dataset gets installed as one of the example datasets in the sf package. The data is stored in the package’s gpkg/ directory4, so we’ll begin by loading it with read_sf() and taking a look at the data with glimpse(), my preview function of choice5:
nc <- read_sf(system.file("gpkg/nc.gpkg",package = "sf"))
glimpse(nc)
## Observations: 100
## Variables: 15
## $ AREA <dbl> 0.114, 0.061, 0.143, 0.070, 0.153, 0.097, 0.062, 0.0...
## $ PERIMETER <dbl> 1.442, 1.231, 1.630, 2.968, 2.206, 1.670, 1.547, 1.2...
## $ CNTY_ <dbl> 1825, 1827, 1828, 1831, 1832, 1833, 1834, 1835, 1836...
## $ CNTY_ID <dbl> 1825, 1827, 1828, 1831, 1832, 1833, 1834, 1835, 1836...
## $ NAME <chr> "Ashe", "Alleghany", "Surry", "Currituck", "Northamp...
## $ FIPS <chr> "37009", "37005", "37171", "37053", "37131", "37091"...
## $ FIPSNO <dbl> 37009, 37005, 37171, 37053, 37131, 37091, 37029, 370...
## $ CRESS_ID <int> 5, 3, 86, 27, 66, 46, 15, 37, 93, 85, 17, 79, 39, 73...
## $ BIR74 <dbl> 1091, 487, 3188, 508, 1421, 1452, 286, 420, 968, 161...
## $ SID74 <dbl> 1, 0, 5, 1, 9, 7, 0, 0, 4, 1, 2, 16, 4, 4, 4, 18, 3,...
## $ NWBIR74 <dbl> 10, 10, 208, 123, 1066, 954, 115, 254, 748, 160, 550...
## $ BIR79 <dbl> 1364, 542, 3616, 830, 1606, 1838, 350, 594, 1190, 20...
## $ SID79 <dbl> 0, 3, 6, 2, 3, 5, 2, 2, 2, 5, 2, 5, 4, 4, 6, 17, 4, ...
## $ NWBIR79 <dbl> 19, 12, 260, 145, 1197, 1237, 139, 371, 844, 176, 59...
## $ geom <MULTIPOLYGON [°]> MULTIPOLYGON (((-81.47276 3..., MULTIP...After staring at the glimpse() output for a bit, I’ll hazard a guess that the variables can be divided into four categories:
| Category | Variables |
|---|---|
| Qualitative (Identifier) | CNTY_, CNTY_ID, NAME, FIPS, FIPSNO, CRESS_ID |
| Quantitative (Incidence Count) | BIR74, SID74, NWBIR74, BIR79, SID79, NWBIR79 |
| Quantitative (Spatial) | AREA, PERIMETER |
| Geometry | geom |
My plan is to join the rows from the Wikipedia table to the nc rows using the county name as the join key, so I’ll probably only keep the NAME and geom columns and the rest can be dropped.
Now I’ll scrape the Wikiepedia page using the rvest package and prepare the column names for joining:
url <- "https://en.wikipedia.org/wiki/List_of_counties_in_North_Carolina"
nc_county_table <- read_html(url) %>%
html_node("table.wikitable") %>%
html_table(header = TRUE) %>%
as_tibble %>%
clean_names(case = "screaming_snake") %>% # remove unwanted characters from names and applies a specific case
rename_all(~ str_remove_all(.x, "_\\d+")) %>%
mutate(NAME = str_remove(COUNTY," County")) %>% # transform COUNTY to match nc$NAME
select(NAME, FIPS_CODE:MAP)
glimpse(nc_county_table)
## Observations: 100
## Variables: 9
## $ NAME <chr> "Alamance", "Alexander", "Alleghany", "Ans...
## $ FIPS_CODE <int> 1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23,...
## $ COUNTY_SEAT <chr> "Graham", "Taylorsville", "Sparta", "Wades...
## $ CREATED <int> 1849, 1847, 1859, 1750, 1799, 1911, 1712, ...
## $ ORIGIN <chr> "Orange County", "Caldwell County, Iredell...
## $ ETYMOLOGY <chr> "The Battle of Alamance which was derived ...
## $ POPULATION_ESTIMATE <chr> "7005153291000000000<U+2660>153,291", "7004370870...
## $ AREA <chr> "7002435000000000000<U+2660>435 sq mi\n(700311270...
## $ MAP <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...The two datasets can now be joined:
nc_ready <- nc %>%
select(NAME) %>%
full_join(nc_county_table, by = "NAME") %>%
rename(YEAR = CREATED) %>% # YEAR is a clearer column name
st_sf
glimpse(nc_ready)
## Observations: 100
## Variables: 10
## $ NAME <chr> "Ashe", "Alleghany", "Surry", "Currituck",...
## $ FIPS_CODE <int> 9, 5, 171, 53, 131, 91, 29, 73, 185, 169, ...
## $ COUNTY_SEAT <chr> "Jefferson", "Sparta", "Dobson", "Currituc...
## $ YEAR <int> 1799, 1859, 1771, 1668, 1741, 1759, 1777, ...
## $ ORIGIN <chr> "Wilkes County", "Ashe County", "Rowan Cou...
## $ ETYMOLOGY <chr> "Samuel Ashe (1725–1813), a Revolutionary ...
## $ POPULATION_ESTIMATE <chr> "7004271430000000000<U+2660>27,143", "70041105200...
## $ AREA <chr> "7002427000000000000<U+2660>427 sq mi\n(700311060...
## $ MAP <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA...
## $ geom <MULTIPOLYGON [°]> MULTIPOLYGON (((-81.47276 3....A couple columns appear to have encoding issues (POPULATION_ESTIMATE, AREA, and MAP), but otherwise the data look as I expected them to.
Brainstorming
Now I’ll begin probing the data for plot ideas. The COUNTY_SEAT column catches my attention first (cities!), but I’m then drawn to YEAR which seems to be the year that each county was formed. Visualizations of temporal data are appealing because they naturally lend themselves to narrative creation. The years in this column tell the story of which counties are old and which are new (relatively speaking), as well as the general pattern of county formation
Let’s have a look at the distribution of the years when the counties were created:
nc_ready %>%
st_set_geometry(NULL) %>%
ggplot(data = ., aes(x = YEAR)) +
geom_histogram() +
theme_min_blogdown() + # a theme customized to match the aesthetics of this blog
theme(axis.title = element_blank())
The histogram above suggests a major increase around 1775 and another smaller one near 1850. Increasing the bins parameter might clarify exactly when these counties were added:
years <- max(nc_ready$YEAR) - min(nc_ready$YEAR) + 1
nc_ready %>%
st_set_geometry(NULL) %>%
ggplot(data = ., aes(x = YEAR)) +
geom_histogram(bins = years) +
scale_y_continuous(breaks = 0:10, minor_breaks = NULL) +
theme_min_blogdown() +
theme(axis.title = element_blank()) 
While not an attractive chart, it clarifies the difference between the spike in counties around 1776 and the small but steady additions seen in the mid-1800s.
This period of rapid growth seems worth exploring as a topic for a data visualization.6 While the histogram above clearly illustrates the number of counties added each year, I’m curious if there is a visually-richer way to tell this story.
I like the linear x-axis because it is a familiar way to representing time. The y-axis, however, feels like an opportunity for improvement. I’ll see what this pattern of county creation looks like when represented as a cumulative count rather than an individual one:
nc_year <- nc_ready %>%
st_set_geometry(NULL) %>%
group_by(YEAR) %>%
summarise(NAME = list(NAME) %>% map_chr(str_c, collapse = ", "),
COUNT = sum(n())
) %>%
mutate(COUNT_CUMULATIVE = cumsum(COUNT)) %>%
arrange(YEAR)
print(nc_year, n=5)
## # A tibble: 55 x 4
## YEAR NAME COUNT COUNT_CUMULATIVE
## <int> <chr> <int> <int>
## 1 1668 Currituck, Pasquotank, Perquimans, Chowan 4 4
## 2 1705 Craven 1 5
## 3 1712 Beaufort, Hyde 2 7
## 4 1722 Bertie, Carteret 2 9
## 5 1729 Tyrrell, New Hanover 2 11
## # ... with 50 more rows
ggplot(data = nc_year, aes(x = YEAR, y = COUNT_CUMULATIVE)) +
geom_col() +
theme_min_blogdown() +
theme(axis.title = element_blank())
This is a definite improvement! The lines act like a rug plot and a bar chart at the same time, drawing attention to the period of dramatic county creation between 1776 - 1779.
Refining the Draft
I’d like to take this draft and run with it, but before I start tweaking the ggplot2 parameters I’ll do some quick stetches on paper to figure out what the final product should look like. I’ve found this step helpful because it provides me with a clear end goal which reduces the amount of time spent messing around with minor changes.
Here’s my sketch of what I’ll try to create:

The idea is to create a combination plot with the county boundaries placed above the county creation history bar chart. I’ll use a label to emphasize the spike in 1779 and distinguish those counties from the rest by giving them a different fill color. The American Revolutionary War will be illustrated with a simple gray rectangle behind the county data.
With this goal in mind, I’ll now implement it using the ggplot2 and patchwork packages. Rather than showing all the iterations I’ll go through, I’ll just list the methods and functions that make it work:
- Polygon Plot:
- Step Plot:
- Augmenting a timeseries plot with a “callout” bar is a common tactic used by economic and financial data analysts.8
ggplot’s layering system makes it relatively straightforward to create this type plot by combininggeom_step()andgeom_col(). - The label for the year with the most counties is created using
group_by(YEAR)andsummarize(), followed by anif_else()that replaces all labels other than the year 1779 with"". - The hollow circle point highlighting the 1779 step is created by taking advantage of R’s point shape options9 and
ggplot’sscale_shape_identity()function.10 - The label for the Revolutionary War is created by adding an additional plot that only contains the
geom_text()layer and is combined with the rest of the step plot using thepatchworkpackage. This is a little heavy-handed but it gets the job done. - The y-axis ticks/labels do not match the panel grid. Normally the ticks and labels are show at the major breaks, but in this plot I want the ticks/labels to show only the min and max while the panel grid will have typical set of major and minor breaks. The way I achieve this is pretty hacky: set major breaks at the min and max, hide the grid panel, and add
geom_hline()andgeom_vline()layers that mimic a grid panel but do not correspond with the major breaks. - I experimented with adding a
fillcolor to the area beneath thegeom_step()line but decided against it because it didn’t add any information.11
- Augmenting a timeseries plot with a “callout” bar is a common tactic used by economic and financial data analysts.8
- Rug plot:
- While
geom_rugexists, I don’t like the way the lines clutter the x-axis, so I create a similar effect usinggeom_col. To do this I add a column to the data (COUNT_RUG) which has a value of4for every year that a county was added. - In order to better distinguish the years were many counties were added, I map the
COUNTvariable togeom_col( alpha = COUNT)and set the scale withscale_alpha(range = c(0.2, 0.8)).12
- While
- Custom themes:
- In order to match the typography of this blog, I create custom
ggplot2themes and install the fonts using theextrafontpackage. - The polygon plot should have anything except the polygons, so I create a version of
theme_voidwhich I calltheme_void_blogdown(). The filled step plot needs axes, labels, and ticks, so a verison oftheme_minimalis created (theme_min_blogdown()) and used to style this plot.13
- In order to match the typography of this blog, I create custom
- Multi-Plot Layout:
- The
patchworkpackage makes it trivial to combine multiple plots - highly recommended! - I arrange the plots with
plot_layout()and fine-tune the sizes using theheightsandwidthsparameters - Labels (title, subtitle, caption) are added using
plot_annotation()
- The
Banging Out the Code
The following code chunks show the steps needed to transform the data and create the composite data graphic. Note: for those interested in running the code on their own computer I recommend copying the entire script from the gist.
max_year <- nc_ready %>%
count(YEAR, sort = TRUE) %>%
slice(1) %>%
pluck("YEAR")
max_year_header <- str_c(max_year,":", sep = "")
nc_year <- nc_ready %>%
group_by(YEAR) %>%
summarise(COUNTY_SEAT = list(COUNTY_SEAT),
NAME = list(NAME),
COUNT = sum(n()),
COUNT_RUG = as.integer(COUNT > 0) * 4
) %>%
mutate(MAX_LGL = COUNT == as.integer(max(COUNT)),
CUMULATIVE = cumsum(COUNT),
LABEL = map_chr(NAME, str_c, collapse = "\n"),
LABEL = if_else(MAX_LGL, str_c(max_year_header, LABEL, sep = "\n"), ""),
SHAPE = if_else(MAX_LGL, 1, 32 ) %>% as.integer()
)
# Check out the result:
print(st_set_geometry(nc_year, NULL),n=3)
## # A tibble: 55 x 9
## YEAR COUNTY_SEAT NAME COUNT COUNT_RUG MAX_LGL CUMULATIVE LABEL SHAPE
## * <int> <list> <list> <int> <dbl> <lgl> <int> <chr> <int>
## 1 1668 <chr [4]> <chr [~ 4 4. FALSE 4 "" 32
## 2 1705 <chr [1]> <chr [~ 1 4. FALSE 5 "" 32
## 3 1712 <chr [2]> <chr [~ 2 4. FALSE 7 "" 32
## # ... with 52 more rowswar <- tibble(
WAR_NAME = "Revolutionary War",
START = as.integer(1775),
MID = as.integer(1779),
END = as.integer(1783)
)# Setup
title <- "1779: The Year of Many Counties"
subtitle <- "In the middle of the American Revolutionary War, North Carolina created nine new counties\nin a single year - more than any other year in the state's history."
caption <- "Source: Wikipedia <https://en.wikipedia.org/wiki/List_of_counties_in_North_Carolina>"
black_15pct <- adjustcolor( "black", alpha.f = 0.15)
black_15pct_no_opacity <- rgb(218,218,218, max = 255)
highlight_red <- "#f03838"
labels <- c("First 4 Counties", "All 100 Counties")
x_intercepts_major <- seq(1700,1900, by = 50)
x_intercepts_minor <- seq(1675,1875, by = 50)
y_intercepts_major <- seq(50,100, by = 50)
y_intercepts_minor <- seq(25,75, by = 50)
year_limits_min <- min(nc_year$YEAR)
year_limits_max <- max(nc_year$YEAR)
# Step plot
gg_step <- ggplot(data = nc_year, aes(x = YEAR, y = CUMULATIVE, label = LABEL)) +
geom_vline(xintercept = x_intercepts_major, alpha = .25, size = .25) +
geom_vline(xintercept = x_intercepts_minor, alpha = .15, size = .15) +
geom_hline(yintercept = y_intercepts_major, alpha = .25, size = .25) +
geom_hline(yintercept = y_intercepts_minor, alpha = .15, size = .15) +
geom_col(mapping = aes(x = YEAR, y = COUNT_RUG, alpha = COUNT)) +
scale_alpha(range = c(0.2, 0.8)) +
geom_rect(inherit.aes = FALSE,
data = war,
mapping = aes(xmin = START, xmax = END, ymin = 0, ymax = Inf),
fill = black_15pct) +
geom_step(size = 1) +
scale_shape_identity() +
geom_point(data = nc_year, aes(x = YEAR, y = CUMULATIVE, shape = SHAPE), fill = "white", size = 3, color = highlight_red) +
geom_label_repel(min.segment.length = .1, segment.colour = "black",point.padding = 1.5,nudge_x = -1, nudge_y = 1, fill = "white", color = "black", size = 2.5,label.size = NA, box.padding = 0.15, family = "Work Sans", fontface = "plain", angle = 0, lineheight = 1.15) +
theme_min_blogdown() +
scale_y_continuous(breaks = c(4,100), labels = labels) +
theme(legend.position = "none",
panel.grid = element_blank(),
axis.title = element_blank(),
axis.ticks = element_line(size = .5),
axis.line = element_line(size = .5))
# Step plot war label
gg_label <- ggplot(data = war, aes(x = MID, y = 0, label = WAR_NAME)) +
scale_x_continuous(limits = c(year_limits_min, year_limits_max)) +
geom_text(size = 2.5,nudge_x = 0,nudge_y = 0, family = "Work Sans", fontface = "plain",
color = "black",
hjust = 0.5, vjust = 0.5, angle = 0, lineheight = 0.9) +
theme_void()
# Map plot
gg_map <- ggplot() +
geom_sf(data = filter(nc_ready, YEAR != max_year), fill = black_15pct_no_opacity, color = "black", size = .1) +
geom_sf(data = filter(nc_ready, YEAR == max_year), fill = "black", color = black_15pct_no_opacity, size = .25) +
coord_sf(datum = NA) +
theme_void_blogdown()
# Combined plot
gg_plot <- gg_map +
{gg_label + gg_step + plot_layout(ncol = 1, heights = c(1,20))} +
plot_layout(ncol = 1, heights = c(1,1.15)) + # composing plots like this is made possible by the patchwork pacakge
plot_annotation(title, subtitle, caption,
theme = theme_min_blogdown()
) Final Result
After all of that, the plot is finally complete! Let’s take a look:
gg_plotConclusion
As I said at the top, polished plots are a ton of work!
When it comes to data visualization, you need to be able to take control of nearly every detail of the image. Packages like ggplot2 and patchwork are powerful tools, but that doesn’t means it’s easy to create a graphic exactly as you envision it. You have to come up with creative workarounds within the limitations of the tools, and to do that you need to become good at searching the documentation and community resources for the help.
I hope that this description of my approach serves as a useful reference to other R users and people who create data visualizations.
DIY & Feedback
If you’d like to reproduce this example on your own computer please download the gist.
Questions, feedback, and suggested improvements are always welcome!
Resources
- Data Visualization by Claus O. Wilke
ggplot2ReferencespatchworkGithub repo READMEggrepelGithub repo README
Check out
?st_readfor an example with the code needed to load it. Additionally, take a look at thedemo/directory of thesfpackage Github repo. There you’ll findnc.Rand in the front-matter there’s a link to the data’s original documentation pdf from thespdeppackage↩For more information on reproducible examples, check out the
reprexpackage.↩See the
spdeppackage vignette pdf for interesting examples of spatial data analysis using the SIDS data.↩The
ncdata are also available in thesfpackage’sshape/, which is useful if the GeoPackage driver isn’t installed (runst_drivers()to check which drivers are available).↩Two other useful packages for exploring a new dataset are the
skimrandvisdatpackages.↩I know that the American Revolutionary War occurred between 1775 and 1783, so the addition of several counties during this time of conflict and transformation is not surprising. This animation shows the actual changes of the boundaries over time, but unfortunately it doesn’t offer any explanation for what caused each change.↩
Source: “ggplot2 Github issue - Cannot remove panel.grid (graticules) from ggplot + geom_sf() #2071”↩
Here’s the plot that served as an inspiration for this example: A History of Home Values by Robert Shiller↩
Source: “ggplot2 Quick Reference: Mapping with scale_shape_identity”↩
A simple example of a “filled step plot” can be found here and a more advanced example can be found here.↩
Source: “ggplot2 References: Get, set, and modify the active theme”↩
{kind=link}